Why SensorGen
The broadest open study of sensor-signal generation
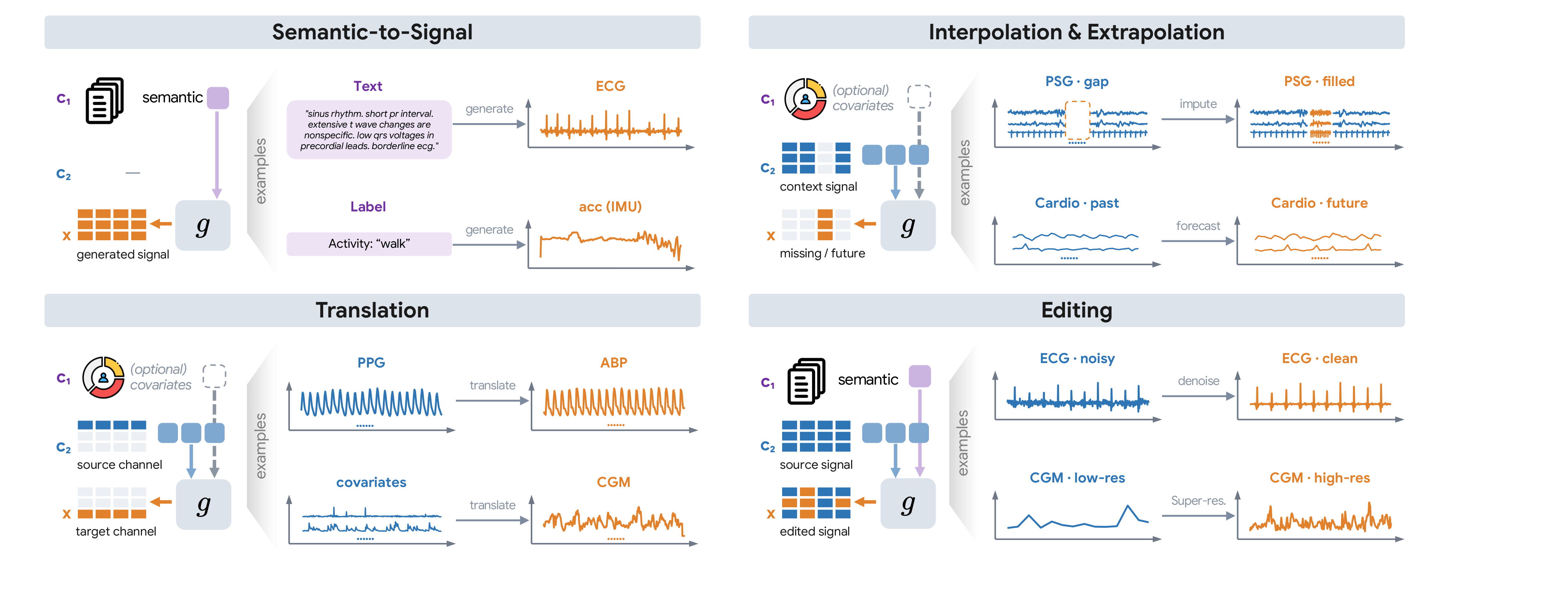
Generative modeling of sensor signals has been fragmented across modalities, datasets, and task formulations, with each method tuned to a single signal type. SensorGen consolidates this landscape into one platform — shared data processing, task construction, training, and evaluation — so that model families, signal properties, and design choices can finally be compared apples-to-apples.

Signal Diversity & Scale
Sampling Frequency
0.0033 Hz → 256 HzSequence Length
102 → 104 stepsTime Span
seconds → 7 daysFour Real-World Data Regimes
Emergency Department
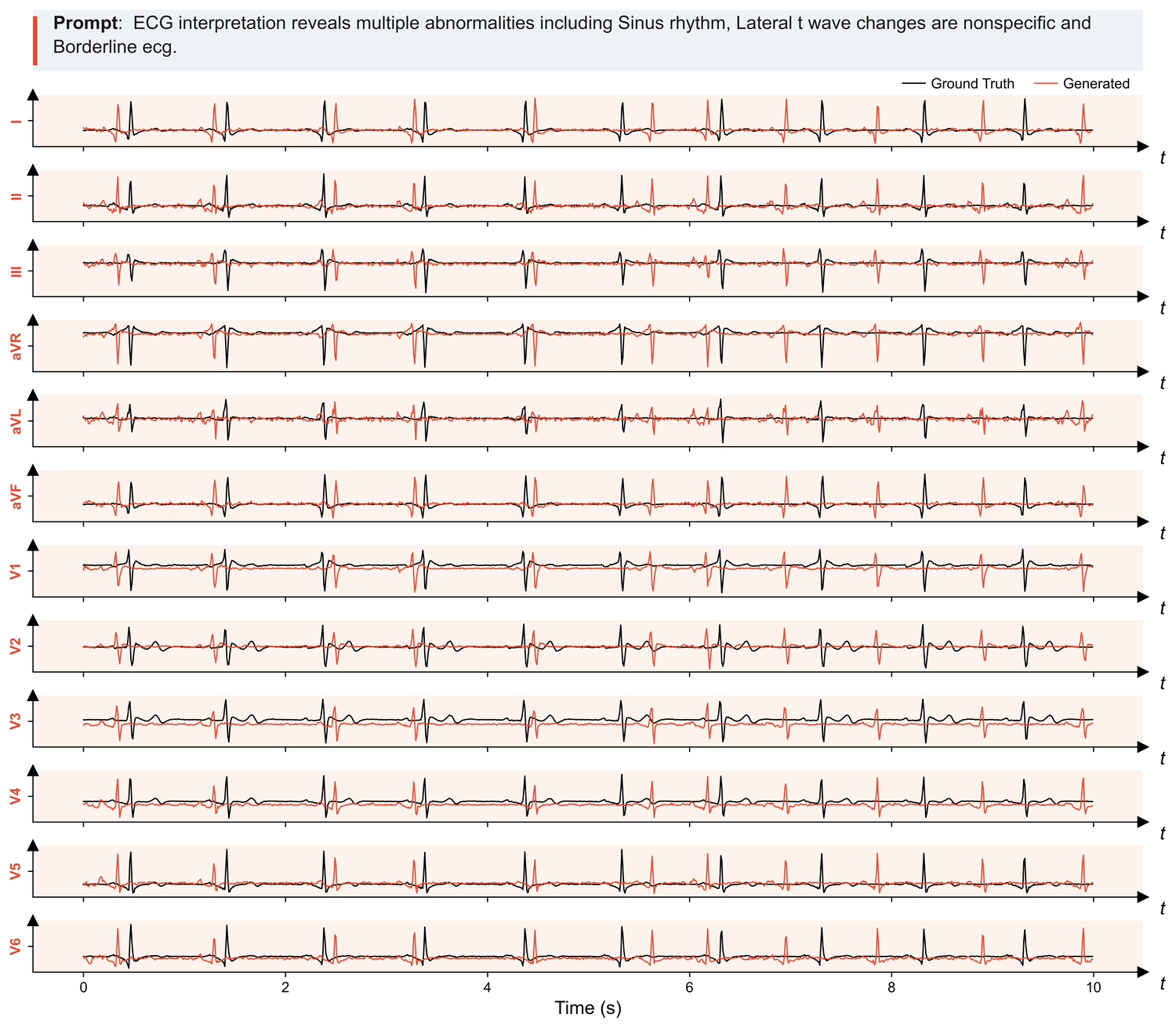
MIMIC-IV ECG — clinical 12-lead electrocardiograms paired with diagnostic reports.
Daily Life
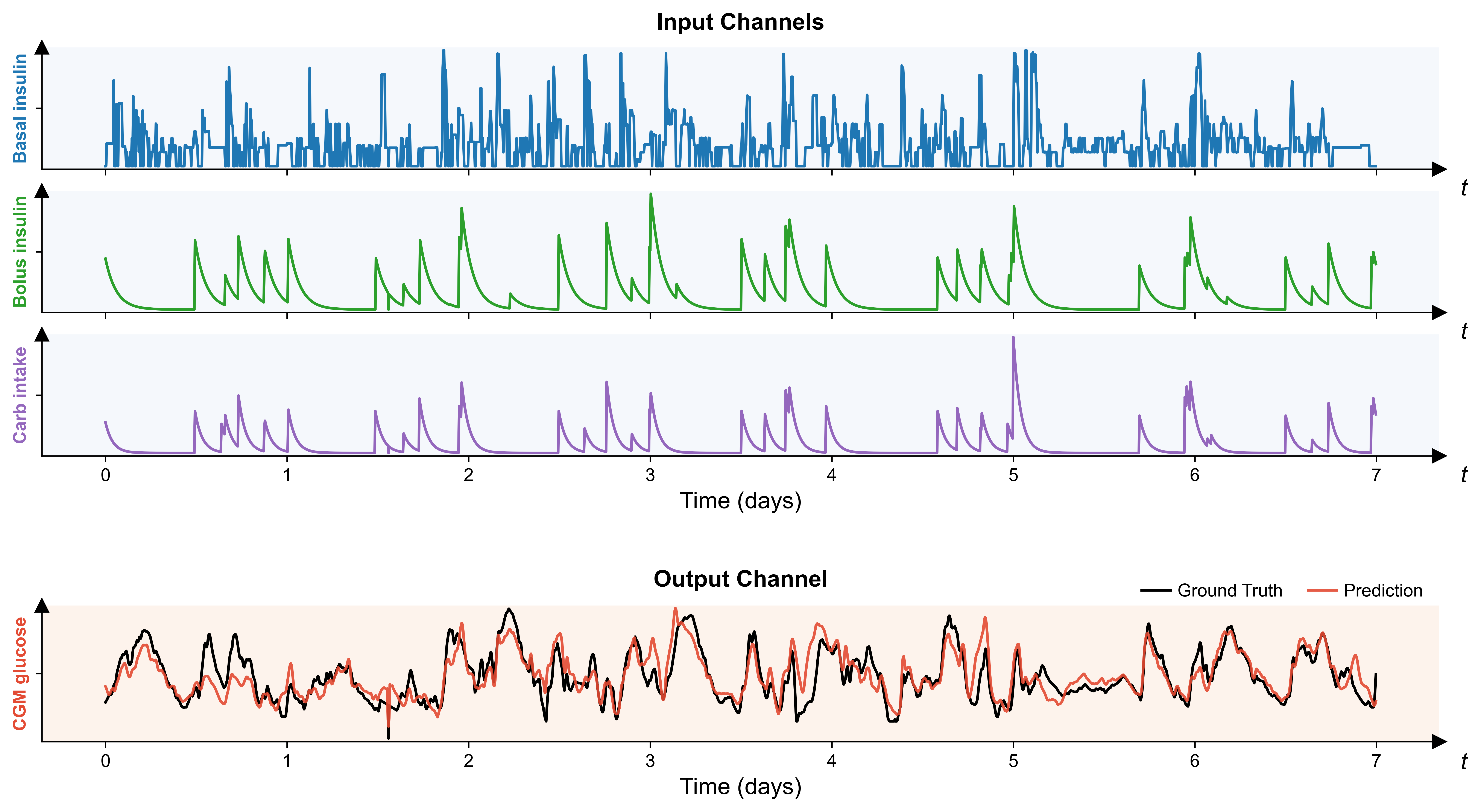
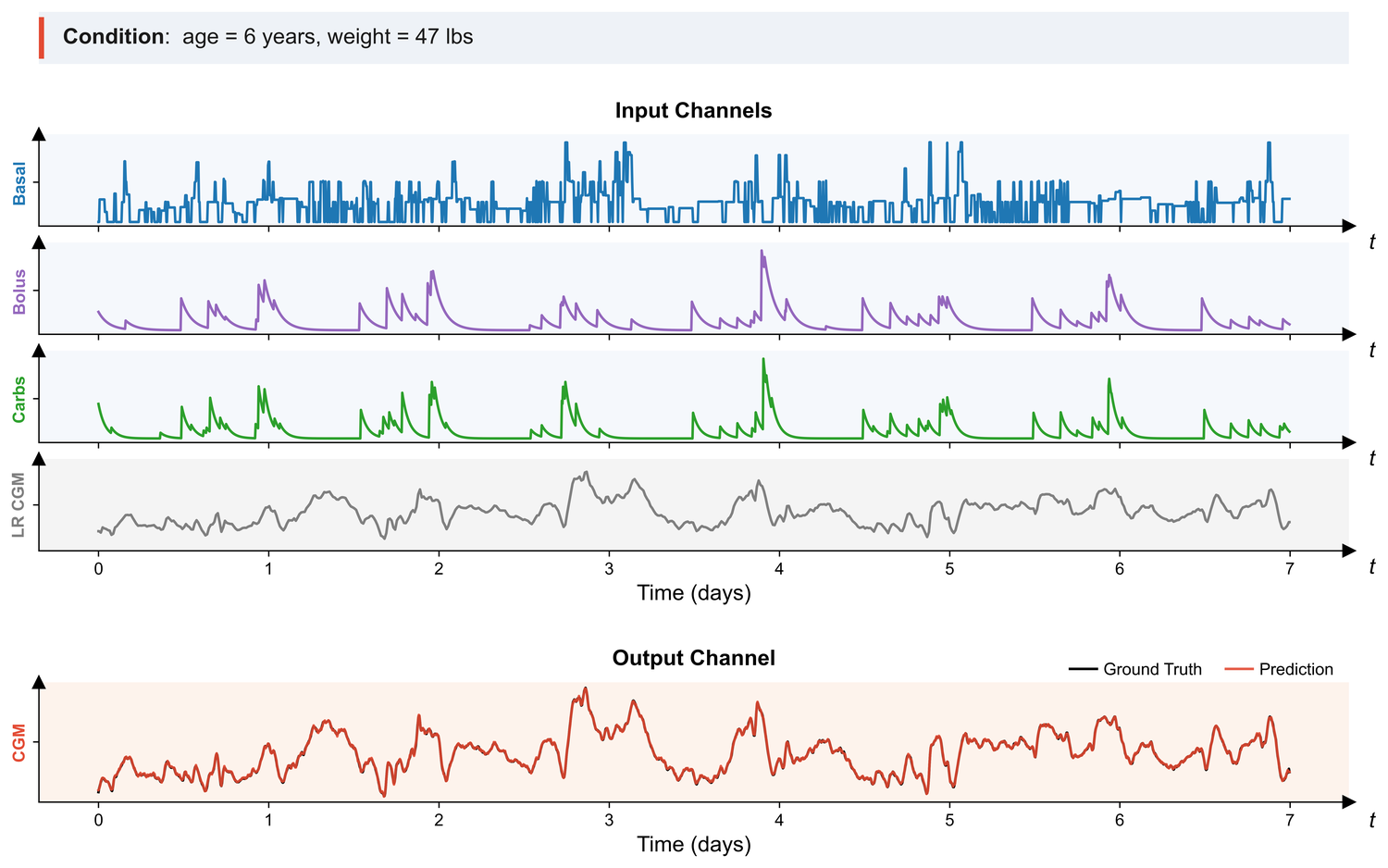
CAPTURE-24, PPG-DaLiA, Metabonet — free-living accelerometry, wearable physiology, and longitudinal metabolic traces.
Lab Study
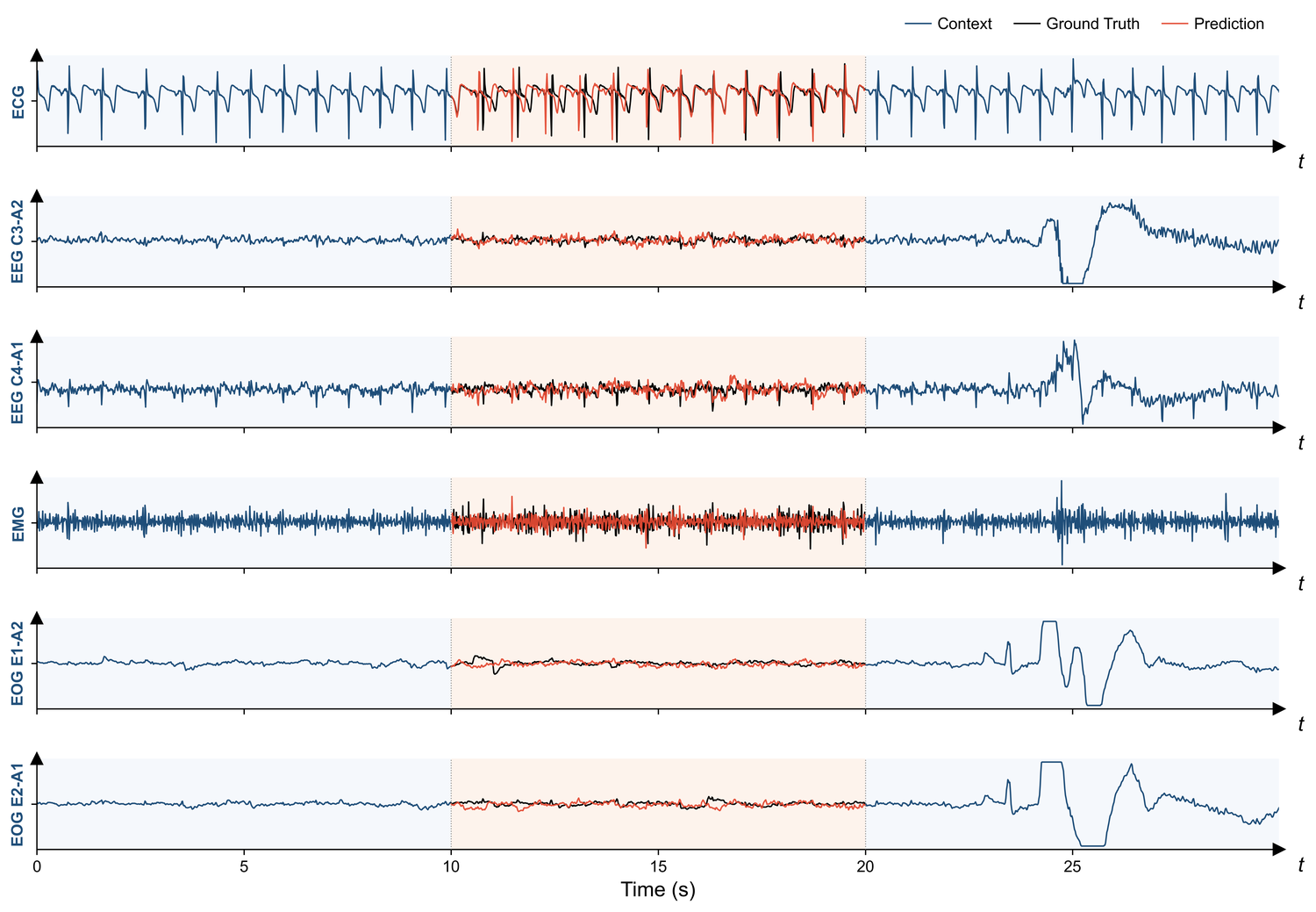
PhyMER, SHHS — controlled affective-state recordings and overnight polysomnography (EEG, ECG, EMG, EOG).
Operation Room
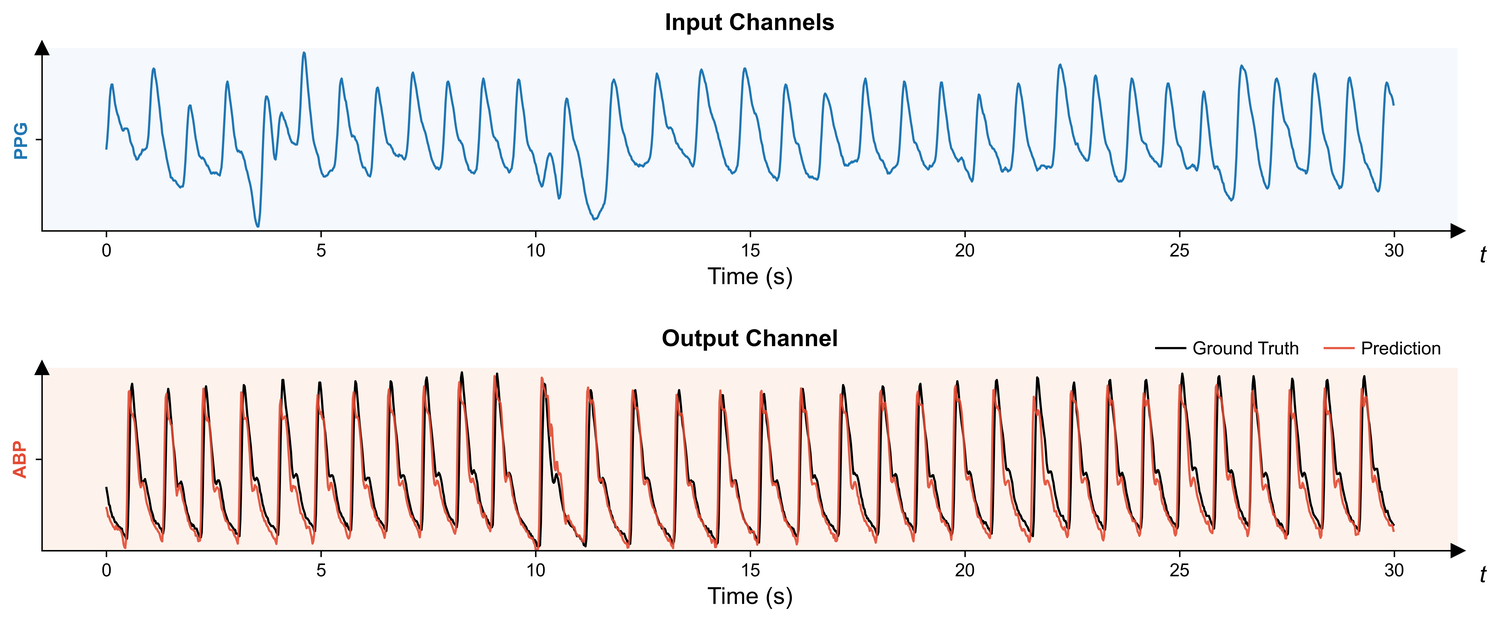
VitalDB — intra-operative waveforms, medication records, arterial blood pressure, PPG, ECG, and NIBP.
Signal Modalities
Click an icon to see where each modality appears.
These settings are organized into 4 task categories and 14 concrete settings. See the task design →